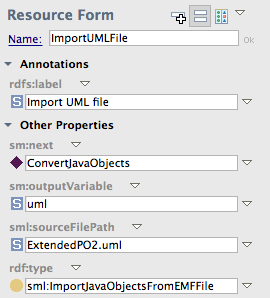
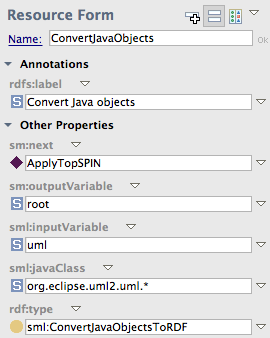
TopQuadrant's visual data processing language
SPARQLMotion is now in routine use in many projects around the world. Its graphical notation and rich set of features makes it a powerful language to import, process and export linked data from almost any format, using Semantic Web technologies. Over the last two years, TopBraid's SPARQLMotion engine has become increasingly robust and it is now fair to say that it is becoming a de-facto standard language for linked data (at least in the professional world where the TBC-ME price tag is not an obstacle).
An important part of turning a (formerly) experimental language into an industry-strength solution is to provide tools that aid developers in the construction and testing phases of their project. In this spirit, we have added a graphical SPARQLMotion Debugger to
TopBraid Composer 3.3. This debugger makes it possible to interrupt an executing SPARQLMotion script, to introspect into variable bindings and arguments, to ask test queries against the current state, and to display the current RDF graph.
Let's look into debugging the SPARQLMotion script shown below.

There are now two execution buttons at the top of the SPARQLMotion graph editor. The green arrow executes the script normally. If a module has been selected, then the script will only execute until this point. The green bug button will execute the script but immediately open the debugger window. The debugger will also be shown whenever a module is reached that has a breakpoint attached to it. To set a breakpoint, select a module and then press the button with the small blue dot. In either case, the debugger will show up as shown below.

The left part of the debugger displays the currently executed modules, including those from nested sub-scripts (shown indented under their parents). You can set additional breakpoints there to make sure you don't miss anything important. The main area of the debugger can be switched between three different tabs, including the Variables tab shown above. This tab displays all current input variable bindings, allowing you to see the exact state of the engine when it enters the current module. Below the variables, you can see the input arguments to the current module. The values of those arguments are shown in exactly the same way as the engine will interpret them, e.g. they will have string templates applied to them already.
The next tab can be used to ask arbitrary SPARQL queries to further explore what the current module will see when it executes. If the module takes a SPARQL query as an input argument, then this will be suggested as the initial query.

Finally, if you wonder about the structure of the input RDF graphs, you can switch to the third tab (shown below). The tree structure of the graphs represents the imports closure (sub-graphs). Having this view will be helpful if you wonder why certain queries don't work as expected - they may operate on a different set of input graphs than you may believe.

When all is said and done, you can use the buttons at the bottom to either continue the execution up to the next breakpoint, or to step into the next executing module. Note that the debugger will also show up when you run web services and TopBraid Ensemble callbacks.
The new SPARQLMotion Debugger addresses one major challenge that many users have: understanding exactly what's happening. SPARQLMotion is now no longer a black box, and there is no longer the need to create artificial debugging and trace output to trace what's happening behind the scenes. I am confident this debugger will significantly reduce the learning curve and create many happy SPARQLMotion users.
 The UISPIN snippet above would be rendered in HTML as follows:
The UISPIN snippet above would be rendered in HTML as follows: